위 문제는 한국데이터산업진흥원의 [SQL 자격검정 실전문제]를 참조하였습니다.
해설은 https://cafe.naver.com/sqlpd 의 글과 참조하여 개인적인 생각을 적은 글입니다.
p.42 6번
다음 중 아래의 데이터 모델과 같은 테이블 및 PK 제약조건을 생성하는 DDL 문장으로 올바른 것은?
(단, DBMS는 Oracle을 기준으로 한다.)

|
1
2
3
4
5
6
|
CREATE TABLE PRODUCT
( PROD_ID VARCHAR2(10) NOT NULL
,PROD_NM VARCHAR2(100) NOT NULL
,REG_DT DATE NOT NULL
,REGR_NO NUMBER(10)
,CONSTRAINT PRODUCT_PK PRIMARY KEY (PROD_ID) );
|
cs |
- 오라클에서는 마지막 문장에서 ALTER TABLE PRODUCT ADD CONSTRAINT ~~ 로 작성을 안하고 위처럼 작성해도 PK가 설정이 된다.
p.44 9번
아래 테이블 T, S, R이 각각 다음과 같이 선언되었다. 다음 중 DELETE FROM T; 를 수행한 후에 테이블에 R에 남아있는 데이터로 가장 적절한 것은?

- S테이블의 C 컬럼은 T테이블의 C컬럼 삭제 시 삭제가 된다.
- R테이블의 B 컬럼은 S테이블의 B컬럼 삭제시 NULL로 바뀐다.
- T 테이블이 전체 삭제가 되면 S테이블의 C컬럼이 삭제가 되는데 CASCADE는 행삭제가 되기 때문에 S테이블 전체가 삭제가 되어 결과적으로 R테이블의 최종 값은 (1, NULL)과 (2, NULL)이 남는다.
p.45 12번
아래와 같은 테이블 구조를 정의하려고 한다. 이때 아직 부서가 정의되지 않은 사원은 기본부서(코드: '0000')로 배치하고, 입사일자(JOIN_DATE) 기준으로 많은 조회가 발생하므로 입사일자에 Index를 생성하려고 한다. 다음 중 올바른 SQL 문장을 2개 고르시오.

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
-- 1번
CREATE TABLE EMP
(EMP_NO VARCHAR2(10) PRIMARY KEY,
EMP_NM VARCHAR2(30) NOT NULL,
DEPT_CODE VARCHAR2(4) DEFAULT '0000' NOT NULL,
JOIN_DATE DATE NOT NULL,
REGIST_DATE DATE NULL );
CREATE INDEX IDX_EMP_01 ON EMP (JOIN_DATE);
-- 3번
CREATE TABLE EMP
(EMP_NO VARCHAR2(10) NOT NULL,
EMP_NM VARCHAR2(30) NOT NULL,
DEPT_CODE VARCHAR2(4) DEFAULT '0000' NOT NULL,
JOIN_DATE DATE NOT NULL,
REGIST_DATE DATE);
ALTER TABLE EMP ADD CONSTRAINT EMP_PK PRIMARY KEY (EMP_NO);
CREATE INDEX IDX_EMP_01 ON EMP (JOIN_DATE);
|
cs |
- NOT NULL은 항상 제시되어 있으면 써야한다 (NULL은 생략 가능)
- PRIMARY KEY를 이미 언급했으면 ALTER TABLE에서 ADD CONSTRAINT로 또 추가하면 에러가 난다.
p.47 14번, 15번 (제약조건 정리)
| 키 | 설명 | 고려사항 |
| 기본키 (PK; Primary Key) |
후보키 중 하나를 선정한 대표키 ex) ID, 주민번호 |
- 중복을 허용하지 않는다. - NULL 값을 허용하지 않는다. |
| 고유키 (Unique Key) |
키에 들어 있는 값들이 전체 자료에 걸쳐 전혀 중복되지 않도록 되어 있는 경우 ex) e-mal |
- 중복을 허용하지 않는다. - NULL 값을 허용한다. |
| 외래키 (FK; Foreign Key) |
다른 릴레이션의 기본키를 참조하는 속성 | - 외래키가 성립하기 위해 참조하고 참조되는 양쪽 릴레이션의 도메인이 서로 같아야 한다. - NULL 값과 중복 값 등이 허용된다. |
| Check | 컬럼에 들어갈 수 있는 값을 제한 | - 범위를 지정 - 지정된 값 외에는 사용할 수 없다. - NULL 값과 중복 값을 허용한다. |
p.47 16번
ALTER, DROP COLUMN
Table 스키마 변경 시 사용하는 SQL문은 DDL로 컬럼 삭제 시 활용되는 문장은 다음과 같다.
ALTER TABLE 테이블명
DROP COLUMN 컬럼명
p.48 18번
RENAME TABLE_NAME
RENAME OLD_OBJECT_NAME TO NEW_OBJECT_NAME
(ANSI 표준 기준, 오라클과 동일함)
p.49 19번
Delete(/Modify) Action
| Action | 설명 |
| Cascade | Master 삭제 시 Child 같이 삭제 |
| Set Null | Master 삭제 시 Child 해당 필드 Null |
| Set Default | Master 삭제 시 Child 해당 필드 Default 값으로 설정 |
| Restrict | Child 테이블에 PK 값이 없는 경우만 Master 삭제 허용 |
| No Action | 참조무결성을 위반하는 삭제/수정 액션을 취하지 않음 |
Insert Action
| Action | 설명 |
| Automatic | Master 테이블에 PK가 없는 경우 Master PK를 생성 후 Child 입력 |
| Set Null | Master 테이블에 PK가 없는 경우 Child 외부키를 Null 값으로 처리 |
| Set Default | Master 테이블에 PK가 없는 경우 Child 외부키를 지정된 기본값으로 입력 |
| Dependent | Master 테이블에 PK가 존재할 때만 Child 입력 허용 |
| No Action | 참조무결성을 위반하는 입력 액션을 취하지 않음 |
p.49 20번
아래와 같은 SQL문에 대해 삽입이 성공하는 SQL문은?

- 실패, 삽입 컬럼을 명시하지 않았을 경우 모든 컬럼을 삽입해야 함
- 실패, 'AB'가 VARCHAR2(1)이 아님, 2바이트임
- 실패, NOT NULL인 AMT가 빠짐
- 성공
- 성공
p.51 23번
개발 프로젝트의 표준은 모든 삭제 데이터에 대한 로그를 남기는 것을 원칙으로 하고, 테이블 삭제의 경우는 허가된 인력만이 정기적으로 수행 가능하도록 정하고 있다. 개발팀에서 사용 용도가 없다고 판단한 STADIUM 테이블의 데이터를 삭제하는 가장 좋은 방법은 무엇인가?
DELETE FROM STADIUM;
- TRUNCATE TABLE STADIUM; : 테이블 자체가 삭제되는 것이 아니고, 해당 테이블에 들어있던 모든 행들이 제거되고 저장 공간을 재사용 가능하도록 해제한다. 로그도 남기지 않는다.
- DROP TABLE STADIUM; : 테이블 구조를 완전히 삭제한다. 로그도 남기지 않는다.
p.51 24번
DISTINCT
중복된 데이터를 1건으로 처리해서 출력
p.52 26번
DROP / TRUNCATE / DELETE 비교
| DROP | TRUNCATE | DELETE |
| DDL | DDL (일부 DML의 성격을 가짐) |
DML |
| Rollback 불가능 | Rollback 불가능 | Commit 이전 Rollback 가능 |
| Auto Commit | Auto Commit | 사용자 Commit |
| 테이블이 사용했던 Storage를 모두 Release |
테이블이 사용했던 Storage 중 최초 테이블 생성시 할당된 Storage만 남기고 Release |
데이터를 모두 Delete해도 사용했던 Storage는 Release되지 않음 |
| 테이블의 정의 자체를 완전히 삭제함 |
테이블을 최초 생성된 초기상태로 만듦 |
데이터만 삭제 |
p.52 28번
데이터베이스 트랜잭션에 대한 격리성이 낮은 경우 발생할 수 있는 문제점
| 문제점 | 설명 |
| Dirty Read | 다른 트랜잭션에 의해 수정되었지만 아직 커밋되지 않은 데이터를 읽는 것을 말한다. |
| Non-Repeatabel Read | 한 트랜잭션 내에서 같은 쿼리를 두 번 수행했는데, 그 사이에 다른 트랜잭션이 값을 수정 또는 삭제하는 바람에 두 쿼리 결과가 다르게 나타나는 현상을 말한다. |
| Phantom Read | 한 트랜잭션 내에서 같은 쿼리를 두 번 수행했는데, 첫 번째 쿼리에서 없던 유령 레코드가 두 번째 쿼리에서 나타나는 현상을 말한다. |
p.53 29번
테이블 A에 대해 아래와 같은 SQL을 수행하였을 때 테이블 A의 ID '001'에 해당하는 최종 VAL의 값이 ORACLE에서는 200, SQL Server에서는 100이 되었다. 다음 설명 중 가장 부적절한 것은? (단, AUTO COMMIT은 FALSE로 설정되어 있다)

AUTO COMMIT FALSE일 경우
- Oracle의 경우
DML : 수동 커밋 필요
DDL : 항상 자동 커밋 (묵시적 수행) - SQL Server
DML : 수동 커밋 필요
DDL : 수동 커밋 필요
p.53 30번
- 트랜젝션 (Transaction) : 데이터베이스의 논리적 연산단위로서 밀접히 관련되어 분리될 수 없는 한 개 이상의 데이터베이스 조작을 가리킨다.
- 트랜젝션의 종료를 위한 대표적 명령어
- 커밋 (Commit) : 데이터에 대한 변경사항을 데이터베이스에 영구적으로 반영
- 롤백 (Rollback) : 데이터에 대한 변경사항을 모두 폐기하고 변경 전의 상태로 되돌림
p.54 31번
아래와 같은 테이블에 SQL 구문이 실행되었을 경우 최종 출력 값을 작성하시오.

- 정답 : 3
- ROLLBACK 구문은 COMMIT되지 않은 상위의 모든 Transaction을 모두 rollback한다.
그니까 처음 commit까지만 반영되어서 단가가 2000인 품목은 '002', '004', '005' 총 3개이다.
p.56 37번
아래와 같은 DDL 문장으로 테이블 생성하고, SQL들을 수행하였을 때 다음 설명 중 옳은 것은?

- Oracle에서 ''을 INSERT하면 NULL값으로 들어감
- SQL Server에서 ''을 INSERT하면 '' 그대로 공백 값이 들어감
p.61 42번
오라클의 날짜형 데이터
오라클의 날짜의 연산은 숫자의 연산과 같다.
- 1/26/60 = 1분
- 1/24/(60/10) = 10분
p.61 43번
SEARCHED_CASE_EXPRESSION => SIMPLE_CASE_EXPRESSION
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
/* [SEARCHED_CASE_EXPRESSION 문장 사례 */
SELECT LOC,
CASE WHEN LOC = 'NEW YORK' WHEN 'EAST'
ELSE 'ETC'
END as AREA
FROM DEPT;
/* [SIMPLE_CASE_EXPRESSION 문장 사례 */
SELECT LOC,
CASE LOC WHEN 'NEW YORK' THEN 'EAST'
ELSE 'ETC'
END as AREA
FROM DEPT;
|
cs |
p.63 46번
단일행 NULL 관련 함수의 종류
| 일반형 함수 | 함수 설명 |
| NVL(표현식1, 표현식2) / ISNULL(표현식1, 표현식2) |
표현식1의 결과값이 NULL이면 표현식2의 값을 출력한다. 단, 표현식1과 표현식2의 결과 데이터 타입이 같아야 한다. NULL 관련 가장 많이 사용되는 함수이므로 상당히 중요하다. |
| NULLIF(표현식1, 표현식2) | 표현식1이 표현식2와 같으면 NULL을, 같지 않으면 표현식1을 리턴한다. |
| COALESCE(표현식1, 표현식2, .....) |
임의의 개수 표현식에서 NULL이 아닌 최초의 표현식을 나타낸다. 모든 표현식이 NULL이라면 NULL을 리턴한다. |
p.70 55번
다음 중 아래 SQL의 실행결과로 가장 적절한 것은?

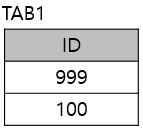
- HAVING COUNT(*) = 2는 개수가 2인 경우를 찾는 것
- ORDER BY (CASE WHEN IN = 999 THEN 0 ELSE ID END) 는 999인 ID를 모두 0으로 바꿔서 정렬만 하라는 의미
- 그러면 999가 0인 채로 맨 위로 올라가기 때문에 SELECT를 하면 다시 999로 보인다.
p.71 57번
ORDER BY 절 특징
- 기본적인 정렬 순서는 오름차순(ASC)이다.
- SQL 문장으로 조회된 데이터들을 다양한 목적에 맞게 특정 컬럼을 기준으로 정렬하는데 사용한다.
- DBMS마다 NULL 값에 대한 정렬 순서가 다를 수 있으므로 주의한다.
- ORDER BY 절에서 컬럼명 대신 Alias 명이나 컬럼 순서를 나타내는 정수를 혼용하여 사용할 수 있다.
- GROUP BY 절을 사용하는 경우 ORDER BT 절에 집계 함수를 사용할 수도 있다.
p.72 59번
SELECT 문장의 실행 순서
FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
p.72 60번
아래의 팀별성적 테이블에서 승리건수가 높은 순으로 3위까지 출력하되 3위의 승리건수가 동일한 팀이 있다면 함께 출력하기 위한 SQL 문장으로 올바른 것은?

|
1
2
3
|
SELECT TOP(3) WITH TIES 팀명, 승리건수
FROM 팀별성적
ORDER BY 승리건수 DESC;
|
cs |
- 해당 값이 동일한 경우 WITH TIES 옵션을 사용한다.
p.73 61번
- 여러 테이블로부터 원하는 데이터를 조회하기 위해서는 전체 테이블 개수에서 최소 N-1개 만큼의 JOIN 조건이 필요하다.
p.74 63번
Join에 대한 설명
- 일반적으로 Join은 PK와 FK 값의 연관성에 의해 성립된다.
- DBMS 옵티마이져는 From 절에 나열된 테이블이 아무리 많아도 항상 2개의 테이블씩 짝을 지어 Join을 처리한다.
- EQUI Join은 Join에 관여하는 테이블 간의 컬럼 값들이 정확하게 일치하는 경우에 사용되는 방법이다.
- EQUI Join은 '=' 연산자에 의해서만 수행되며, 그 이외의 비교 연산자를 사용하는 경우에는 모두 Non EQUI Join이다.
- 대부분 Non EQUI Join을 수행할 수 있지만, 때로는 설계상의 이유로 수행이 불가능한 경우도 있다.
p.74 64번
다음 SQL의 실행 결과로 맞는 것은?
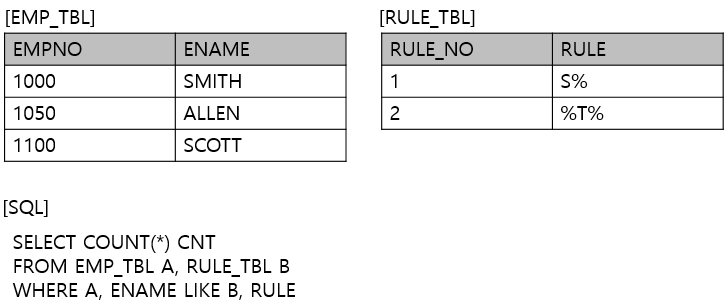
- 정답 : 3번, 4
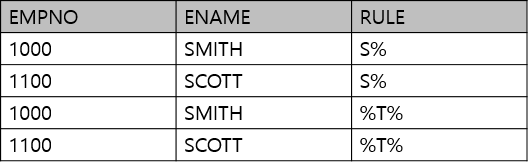
- S%는 S로 시작하는 ENAME으로 SMITH와 SCOTT
- %T%는 ENAME이 중간이 들어가는 것으로 SMI'T'H, SCO'T'T 총 4개이다.
'SQLD > 노랭이 SQL 풀이' 카테고리의 다른 글
| 3-2. 노랭이 SQL 풀이(65번~127번) (0) | 2021.09.01 |
|---|

댓글